
My Recent Research Projects
Lpheada- Labelled Public HEAlth DAtaset: A multicountry, longitudinal, and fully labelled dataset for public health surveillance research
![]()

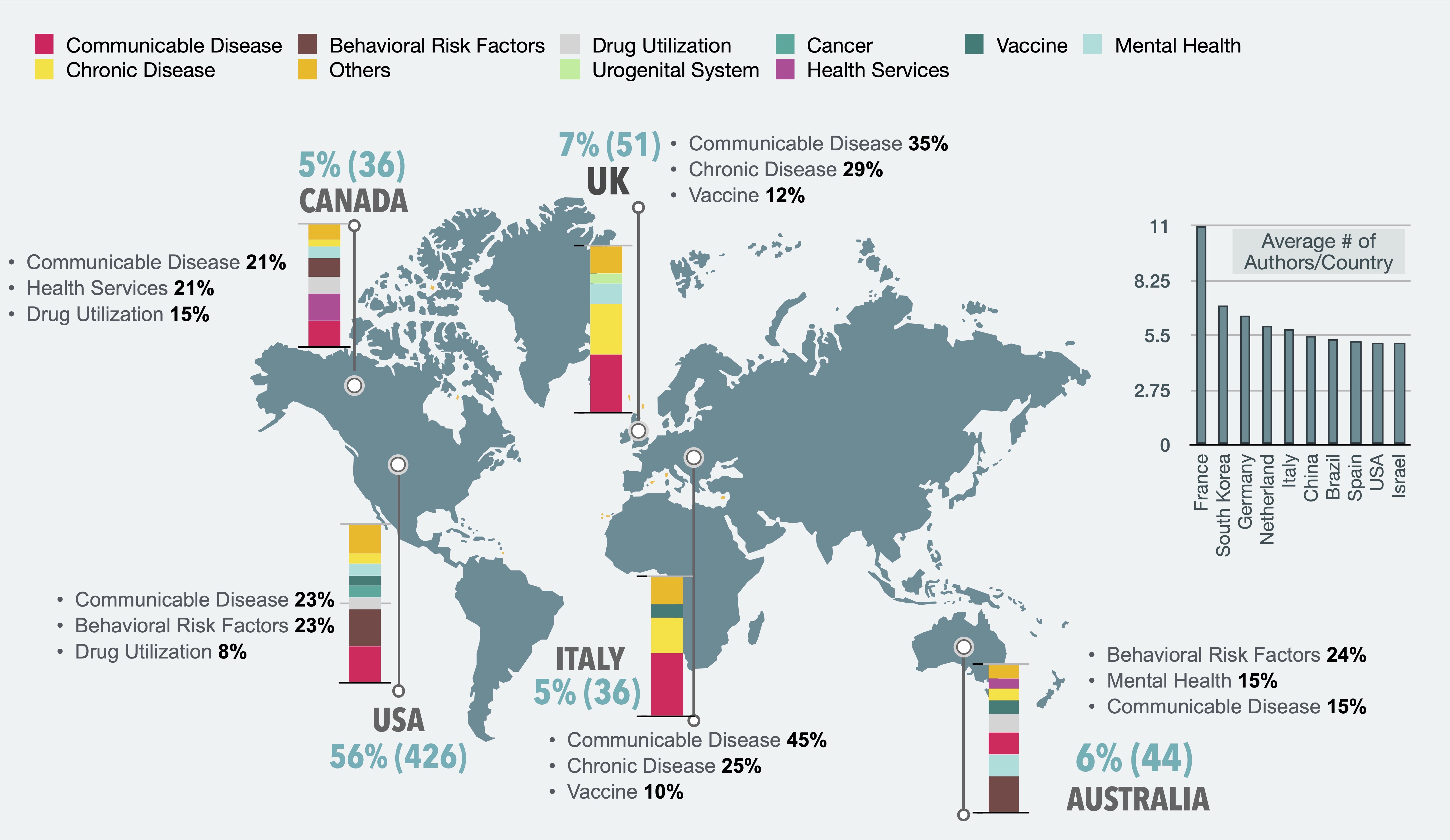
In this research, I developed a multicountry, longitudinal, and fully Labelled digital public health dataset of tweets that originated in Australia, Canada, the United Kingdom (UK), or the United States (US) between November 28$^{th}$ 2018 to June 19$^{th}$ 2020. This dataset contains 366,405 crowd-generated labels (three labels per tweet) for 122,135 PASS-related tweets (out of 1,902,980,841 tweets), labelled by 708 unique annotators on Amazon Mechanical Turk (AMT). In addition to crowd-generated labels, this dataset provides details about the three critical components of any public health surveillance system, including place, time, and demographics (gender, age-range) associated with each tweet. I used machine learning, latent semantic analysis, linguistic analysis, and label inference analysis to validate different components of the dataset. Moreover, I used narrative visualizations to complement the inference methods provided for generating and interpreting different data records of the dataset.
Digital Public Health Surveillance (DPHS)
In this research, I utilized natural language processing, qualitative analysis, and visualization techniques to consolidate and characterize the existing research on DPHS and identify areas for further research. In this research, we conducted a comprehensive systematic scoping review of 755 articles on DPHS published from 2005 to January 2020. The studies included in this review were from 54 countries and utilized 26 digital platforms to study 208 sub-categories of 49 categories associated with 16 public health surveillance (PHS) themes. In addition to discussing the potentials of using Internet-based data as an affordable and instantaneous resource for DPHS, this research also highlights the paucity of longitudinal studies and the methodological and inherent practical limitations underpinning the successful implementation of a DPHS system. Little work studied Internet users’ demographics when developing DPHS systems, and 39% (291) of studies did not stratify their results by geographic region. A clear methodology by which the results of DPHS can be linked to public health action has yet to be established, as only six (0.8%) studies deployed their system into a PHS context. I also developed an interactive visual dashboard to provide insights into the findings with a multidimensional and more granular conceptual structure that is difficult to articulate in text alone.
Crowdsourcing for machine learning in public health surveillance
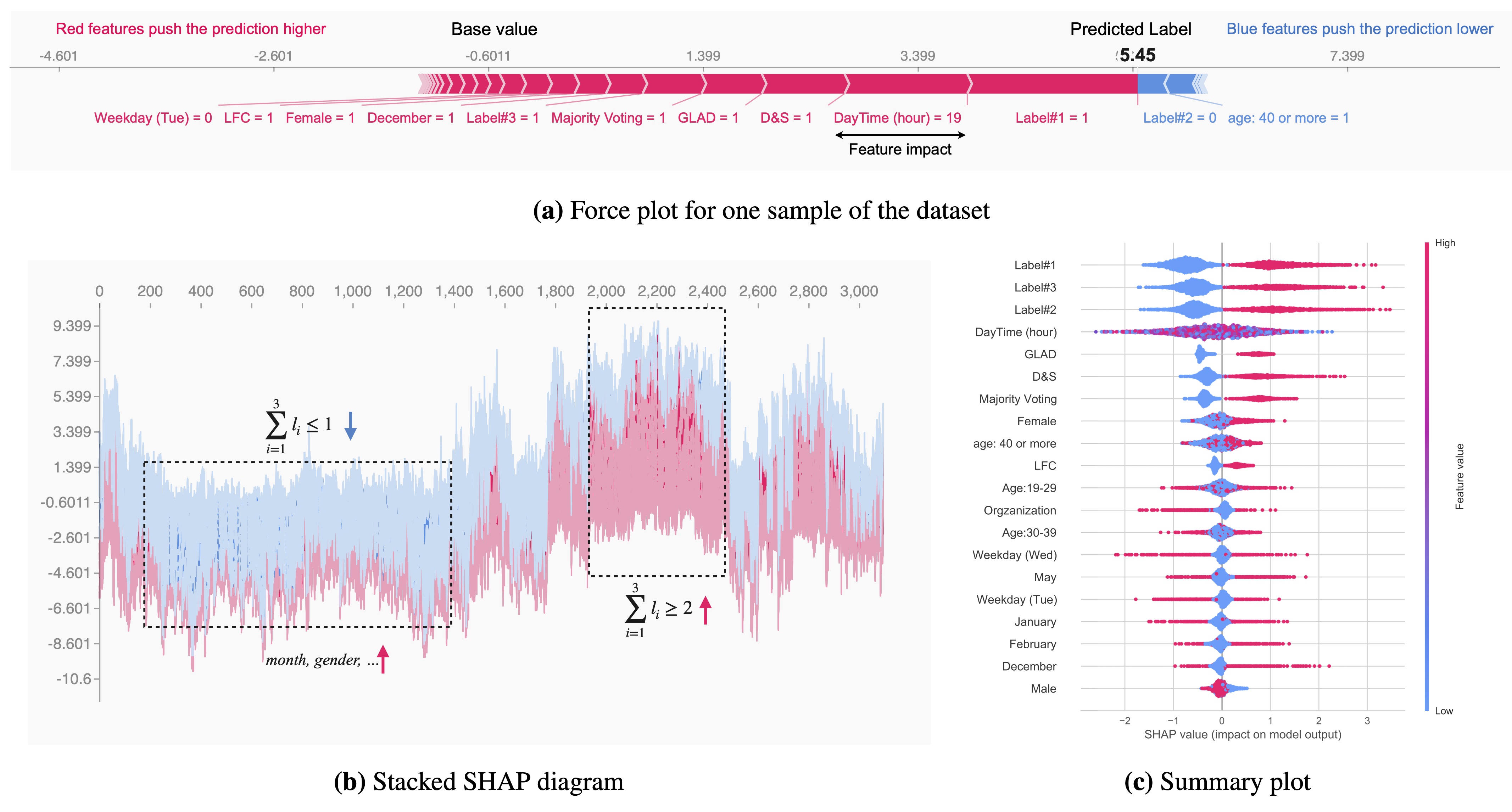
To explore and evaluate the application of crowdsourcing, in general, and Amazon Mechanical Turk (AMT), in specific, for developing digital public health surveillance systems, I developed a data collection/cleaning/labelling pipeline to collect 296,166 crowd-generated labels for 98,722 tweets, labelled by 610 AMT workers, to develop machine learning (ML) models for detecting behaviours related to physical activity, sedentary behaviour, and sleep quality (PASS) among Twitter users. To infer the ground truth labels and explore the quality of these labels, I studied four statistical consensus methods that are agnostic of task features and only focus on worker labelling behaviour. Moreover, to model the meta-information associated with each labelling task and leverage the potentials of context-sensitive data in the truth inference process, I developed seven ML models, including traditional classifiers (offline and active), a deep-learning-based classification model, and a hybrid convolutional neural network (CNN) model. While most of the crowdsourcing-based studies in public health have often equated majority vote with quality, the results of our study using a truth set of 9,000 manually labelled tweets show that consensus-based inference models mask underlying uncertainty in the data and overlook the importance of task meta-information. Our evaluations across three public health datasets show that truth inference is a context-sensitive process, and none of the studied methods in this research was consistently superior to others in predicting the truth label. I also provide a set of practical recommendations to improve the quality and reliability of crowdsourced data.
Predicting Discharge Destination of Critically Ill Patients Using Machine Learning
In this research, we proposed and implemented different machine learning architectures to determine the efficacy of the Acute Physiology and Chronic Health Evaluation (APACHE) IV score as well as the patient characteristics that comprise it to predict the discharge destination for critically ill patients within 24 hours of ICU admission. To achieve this, I conducted a retrospective study of ICU admissions within the eICU Collaborative Research Database (eICU-CRD) populated with de-identified clinical data from adult patients admitted to an ICU between 2014 and 2015. Machine learning models were developed to predict four discharge categories: death, home, nursing facility, and rehabilitation. These models were trained and tested on 115,248 unique ICU admissions. I used hierarchical and ensemble classifiers to further study the impact of imbalanced testing set on the performance of our predictive models. Amongst all of the tested models, XGBoost provided the best discrimination performance with an area under the receiver operating characteristic curve of 90%. Incorporating these models into clinical decision support systems may assist patients, caregivers, and the ICU team to begin disposition planning as early as possible during the hospitalization.